


L’Intelligence Artificielle (ou IA) soulève de nombreuses questions en relation avec les droits de propriété industrielle, tant sur la création d’une œuvre ou d’une invention, que sur la protection de l’IA par les droits de la PI.
Qu’est ce que l’IA ?
Définition
Mais pour bien parler de l’IA, il va falloir un peu expliquer ce que cela est (et surtout ce que ce n’est pas…).
Une Intelligence Artificielle n’est en réalité qu’un programme d’ordinateur, ni plus, ni moins. Mais un programme d’ordinateur un peu particulier : un humain n’a pas spécifiquement programmé son fonctionnement, mais ce programme a « appris » son fonctionnement en analysant un grand nombre de données d’apprentissage (nous allons l’expliquer ci-dessous).
Il ne faut pas voir une « intelligence » particulière derrière ces IA : les IA ne font que ce qu’elles ont appris, sans réflexion aucune.
De nombreuses personnes ont cherché à donner une définition aux IA :
- Les IA sont « les programmes informatiques qui s’adonnent à des tâches qui sont, pour l’instant, accomplies de façon plus satisfaisante par des êtres humains, car elles demandent des processus mentaux de haut niveau tels que : l’apprentissage perceptuel, l’organisation de la mémoire et le raisonnement critique » (Marvin Lee Minsky) ;
- Les IA sont « les programmes informatiques à qui l’on confie des tâches dont même l’humain ne saurait pas véritablement définir les règles sous-jacentes » (Moi)
Quelques exemples d’IA
L’IA englobe un très grand nombre de concepts que j’ai essayé de regroupé dans le schéma suivant (qui n’est clairement pas complet) :
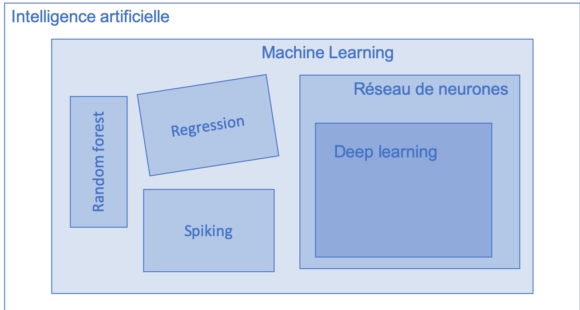
Tout cela pour dire qu’il ne faut pas tout mélanger : l’IA ce n’est pas du deep-learning et réciproquement …
Fonctionnement de quelques IA
Fonctionnement des méthodes de régression
Les méthodes de régression sont principalement utilisées pour essayer de déterminer des relations entre variables.
Par exemple, supposons que mes variables sont :
- l’âge d’une personne ;
- le pourcentage de ses cheveux blancs.
Dans cet exemple très simple, il suffit de prendre un grand nombre de personnes, d’analyser les cheveux et de noter leur age et nous aurons une courbe de ce type.
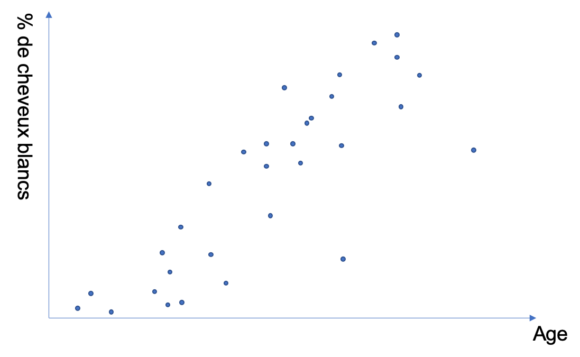
Bien entendu, cela n’est pas suffisant : vous n’avez qu’un nuage de points. Même si un humain voit ici globalement la relation qui se dégage, il ne faut pas oublier que l’on peut généraliser le problème à 800 variables et, dans cette situation, c’est un peu plus complexe à visualiser…
Dès lors, nous avons recours à des méthodes dites de régression (linéaire, polynomiale, logarithmique, etc.) afin de déterminer la courbe ou la surface qui s’adapte le mieux au nuage de points.
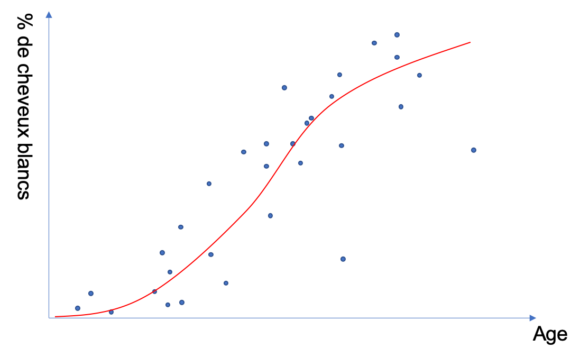
Au final, la courbe rouge va nous donner la relation entre les différentes variables (et même l’incertitude concernant cette relation, c’est magique).
Fonctionnement d’un réseau de neurones
L’idée sous-jacente d’un réseau de neurones est de « mimer » le fonctionnement de nos neurones, mais dans leur fonctionnement le plus basique.
Dans un cerveau, chaque neurone possède un axone qui agit comme un fil électrique, en conduisant l’influx nerveux (sous la forme d’un potentiel d’action) vers le neurone voisin, assurant ainsi l’activité fonctionnelle du cerveau.
Néanmoins, si la somme des influx nerveux arrivant sur l’axone ne dépasse pas une certaine valeur (seuil d’excitabilité du neurone), l’axone ne relaye pas le message nerveux : nous avons ainsi à faire à un mécanisme de seuillage.
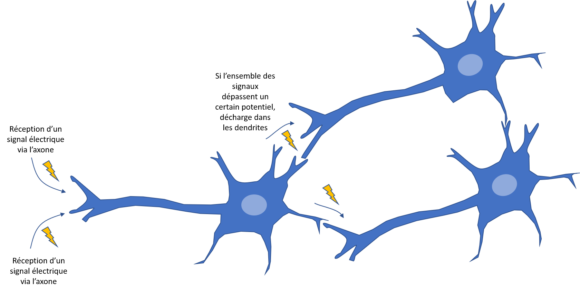
Les informaticiens ont fait exactement la même chose, mais en remplaçant les neurones du cerveau par des « blocs logiques ».
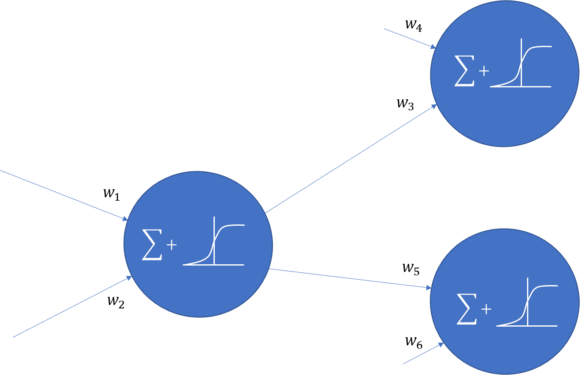
Ainsi, chaque neurone transmet des valeurs à ses voisins. Le neurone recevant des valeurs va alors sommer celles-ci en les pondérant avec des poids dépendant des liens (w1, w2, etc.). Cette somme va alors être seuillée à l’aide d’une fonction de seuil (comme ici la fonction sigma).
Bien entendu, nous n’avons pas 3 neurones, mais bien plus en pratique. Il existe de nombreuses architectures de réseaux de neurones, mais voici à quoi pourrait ressembler une implémentation (5 paramètres d’entrée et 1 paramètre de sortie).
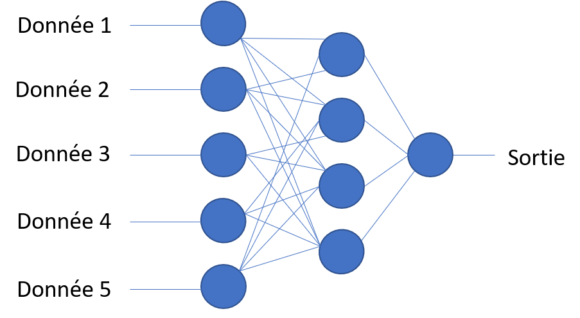
Toute « l’intelligence » contenue dans les réseaux de neurones réside dans la bonne détermination desdits poids. Ainsi, ces poids vont être déterminés en cherchant à résoudre le problème d’optimisation suivant : « Connaissant un grand nombre de données d’entrée et de sortie correspondante, quelles sont les valeurs des poids permettant de maximiser la réponse du réseau ».
Pour résoudre ce problème d’optimisation, on initialise souvent les poids de manière quelconque et on va essayer de les modifier progressivement pour essayer d’optimiser la sortie.
Tant que le résultat du réseau n’est pas celui attendu (ou sa taux d’erreur n’est pas inférieur à un seuil prédéterminé), on continue de chercher des valeurs pour les poids
(Oui, je sais… mon exemple est formellement simpliste et donc faux pour les puristes, mais c’est pour expliquer simplement).
Fonctionnement d’un réseau de neurones de type « Deep-learning »
En réalité, un réseau de type « Deep-learning » est très très proche conceptuellement d’un réseau de neurones, mais le nombre de couches est bien plus élevé.
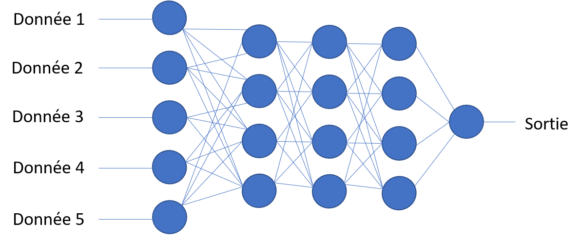
Il faut bien comprendre que les réseaux de type « Deep-learning » possèdent un très grand nombre de poids ou de paramètres, et il peut être très complexe de les faire converger lors de l’apprentissage (i.e. la résolution du problème d’optimisation peut être ardue).
Les réseaux de type « Deep Learning » ont néanmoins émergé ces dernières années, car la puissance de calcul a largement augmenté ces dernières années, notamment grâce à l’utilisation des cartes graphiques.
Les réalisations techniques en lien avec l’IA
La brevetabilité
La brevetabilité des inventions réalisées par IA
Principe
Il peut arriver que l’IA « trouve » des solutions techniques à des problèmes que l’Homme s’était posés depuis longtemps.
Ces solutions peuvent être dans le domaine médical (ex. identification de nouvelles molécules pouvant avoir un effet thérapeutique) dans le domaine de la mécanique (ex. identification d’un profil particulier d’aile d’avion ayant une portance forte) ou dans n’importe quel autre domaine technologique.
Problème concernant la notion d’invention
La question que l’on peut tout de suite se poser est : est-ce qu’une invention faite par un ordinateur est une invention ?
Heureusement, l’A52(1) CBE nous propose une définition de l’invention :
Les brevets européens sont délivrés pour toute invention dans tous les domaines technologiques, à condition qu’elle soit nouvelle, qu’elle implique une activité inventive et qu’elle soit susceptible d’application industrielle.
Ainsi, nous voyions bien qu’il n’existe pas de difficulté : l’invention est définie par son application (i.e. chose nouvelle et inventive dans un domaine technologique) et non pas par son origine ou sa genèse.
Dès lors, une invention peut tout à fait être qualifiée d’ « invention » si son application est technologique.
Problème concernant l’activité inventive
Certains ont pu dire qu’il n’existait pas d’activité inventive pour une invention réalisée à partir d’IA car l’effort de l’inventeur était nul.
Je ne peux qu’être en désaccord.
En effet, l’effort de l’inventeur ou la difficulté qu’il a eu pour inventer ne sont pas des critères pertinents pour évaluer l’activité inventive : l’exigence d’activité inventive repose sur la difficulté pour un homme du métier d’arriver à l’invention à partir des documents de l’art antérieur et non sur la difficulté qu’a rencontré, en pratique, l’inventeur.
Par exemple, cela ne viendrait à l’esprit de personne de dire qu’un inventeur ne peut pas protéger son invention car il l’a trouvé par hasard (et cela arrive assez souvent).
Bien entendu, il serait possible d’argumenter que l’homme du métier est une IA (ou un homme utilisant une IA) mais cette approche conduirait inéluctablement à considérer que toutes les inventions sont évidentes (voir « Everything is obvious » de Ryan Abbott).
Problème concernant la suffisance de description
Certains ont soutenu qu’une invention réalisée par une IA serait insuffisamment décrite, car on ne connait pas le processus inventif qui a amené l’invention.
C’est, il est vrai, un problème des IA : le plus souvent, elles donnent un résultat, mais peinent à expliquer pourquoi un tel résultat est donné.
Je suis définitivement en désaccord avec cette position, car la suffisance de description (A83 CBE) ne vise pas à décrire comment l’invention a été conceptualisée, mais vise à s’assurer qu’un tiers, au vu de la description, puisse réaliser l’invention.
Dès lors, il n’est nul besoin de savoir pourquoi l’invention fonctionne. Il suffit que l’homme du métier puisse vérifier que l’invention fonctionne en la réalisant.
Problème concernant la notion d’inventeur
La CBE n’a aucune définition de la notion d’inventeur.
Pour autant, l’interprétation généralement acceptée est le fait que l’inventeur, au sens de l’A60(1) CBE, est une personne « naturelle » ou un humain (i.e. natural person).
En effet, comment accepter que des « droits » sur l’invention appartiennent à une machine ou un algorithme, sachant qu’aucun droit national (i.e. des états membres) ne prévoit une propriété attachée à une entité autre qu’un humain.
Mais est-ce un vrai problème ?
Tout d’abord, la CBE exige seulement qu’on désigne un inventeur. Il n’existe pas de sanction si l’inventeur n’est pas le bon ou s’il n’existe même pas (voir les exigences relatives au dépôt en Europe).
Mais en vérité, ce n’est même pas le sujet pour moi : la véritable question est de savoir quel est l’acte inventif et quelle est la personne qui réalise cet acte.
En effet, il est assez clair qu’une IA n’est pas plus qu’un programme informatique aidant un humain. L’humain va choisir comment utiliser l’IA, va choisir le jeu de données permettant de l’entrainer, va regarder les données de sortie pour évaluer leur pertinence et leur applicabilité au problème que ce dernier se pose.
Dès lors, il n’existe pas vraiment de différence avec l’utilisation par cet humain d’un simulateur / d’un calculateur qui va aider cette personne. Il ne viendrait à l’esprit de personne de dire « l’inventeur n’a pas réalisé d’invention, car il a utilisé un ordinateur pour réaliser son invention ».
Ainsi, il est toujours possible d’argumenter que l’inventeur est la personne manipulant l’IA afin d’obtenir le résultat souhaité.
Problème concernant la titularité
Concernant la titularité de l’invention, nous pouvons nous demander si le titulaire de l’IA peut déposer une demande de brevet visant une invention sortie du chapeau d’une IA.
A mon sens, et en droit européen, cela ne pose guère de difficulté, car l’A60(1) CBE dispose que l’invention appartient à l’inventeur ou à son ayant cause.
Pour autant (et même si nous devions considérer que l’inventeur est véritablement une machine), le défaut de droit à déposer un brevet (voir inventions déposées par une personne non-habilitée) ne peut être invoqué que par le véritable titulaire des droits.
De même, en France, la nullité du brevet pour défaut de titularité des droits (A138(1) e) CBE) est une nullité relative qui ne peut être invoquée que par le véritable titulaire (voir la nullité en France).
Donc, pour faire simple, personne ne peut remettre en cause un brevet sous prétexte que le titulaire du titre l’aurait volé à une machine…
Quelques exemples
Pour bien vous montrer que cela n’est pas un sujet purement théorique, nous avons vu récemment plusieurs demandes de brevet déposées devant l’OEB visant des inventions ayant été faite par une IA.
Certaines de ces inventions ont été faites par DABUS (qui lui même est déposé… EP2360629 (A3)).
La première invention vise un conteneur ayant des parois fractales permettant ainsi de solidariser deux conteneurs de manière simple.
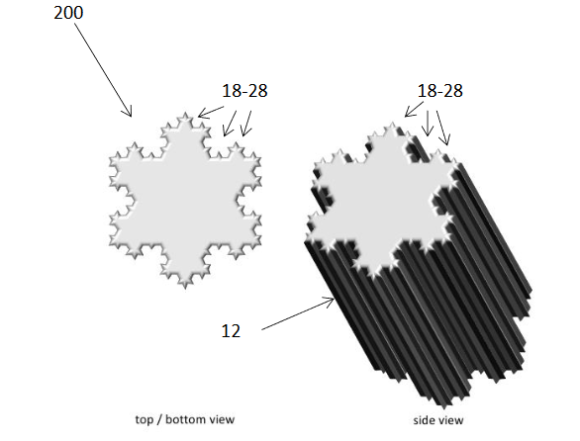
La deuxième invention vise un système d’alerte (via le clignotement d’une diode) ayant une séquence de répétition fractale et permettant ainsi une meilleure reconnaissance par un œil humain.
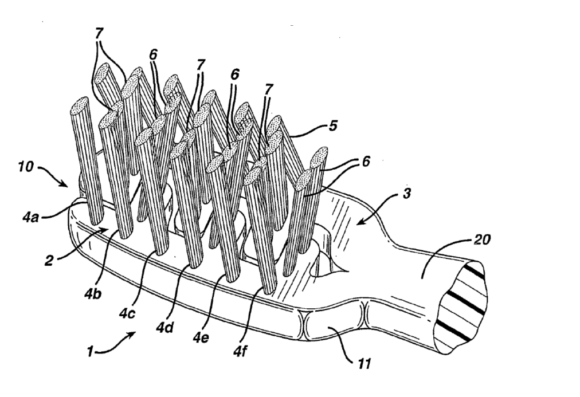
Dans un autre domaine technique, nous pouvons évoquer cette invention de Gillette (EP1284621B1) concernant les brosses à dents dont les « touffes » s’entrecroisent de manière particulière. Et ceci, grâce à la « Creativity Machine » de S. Thaler…
La brevetabilité des inventions mettant en œuvre une IA
Ici, nous nous situons dans le cas où l’invention est véritablement dans la mise en œuvre d’une IA (ex. la reconnaissance d’image avec une IA).
Le concept inventif peut se situer à plusieurs endroits :
- dans la sélection particulière du jeu de données pour l’apprentissage,
- dans l’architecture des réseaux de neurones utilisée pour une tâche spécifique,
- dans la gestion de la mémoire lors de l’apprentissage,
- etc.
Pour ce sujet très différent, je vous redirige vers mon article sur les inventions de type mixte en Europe.
Protection des modèles des IA
Nous avons vu que les inventions réalisées par une IA ou mettant en œuvre une IA pouvaient être protégées par le droit des brevets.
Pour autant, l’IA fait intervenir d’autres entités comme le modèle (ex. la configuration des réseaux de neurones).
Le modèle des IA est souvent très complexe à obtenir, car demande une sélection bien particulière des données d’entrainement et demande beaucoup d’efforts (ex. en termes de puissance de calcul ou en termes d’effort humain pour formater de manière intelligente les données d’entrées).
Ainsi, comment les protéger ?
A mon sens, il existe deux pistes :
- la protection des programmes d’ordinateur par le droit d’auteur ;
- la protection des bases de données par un droit ad-hoc.
En effet, le fait que l’IA reste un programme d’ordinateur motive l’analogie possible avec les programmes d’ordinateur (i.e. logiciels). Ce qui ressemble le plus à l’entrainement d’une IA est la compilation du code source dans un code compilé : l’entrainement d’une IA est une sorte de compilation d’un système dont le but est de rendre ce système conforme aux attentes de l’utilisateur.
Dès lors il est possible d’envisager que le modèle de l’IA est protégé par les dispositions du droit d’auteur relatif au logiciel (L112-2 CPI).
Je rappelle la définition du logiciel donnée par l’Académie Française dans son dictionnaire (9ème édition) est un « Ensemble structuré de programmes remplissant une fonction déterminée, permettant l’accomplissement d’une tâche donnée« . L’IA semble bien rentrer dans cette définition.
Mais il est également possible de faire une analogie avec les bases de données.
En effet, comme je l’ai dit précédemment, le modèle d’une IA est un ensemble de configuration / de poids / etc. Autrement dit, c’est une sorte de base de données de paramètre de configuration.
Dès lors, pourquoi ne pas appliquer le droit ad-hoc prévu par l’article L112-3 CPI et la directive 96/9/CE du 11 mars 1996 ?
Selon cette directive (et son interprétation par la CJUE), une base de données doit avoir les caractéristiques suivantes :

Je pense que l’on peut considérer que les paramètres d’un modèle ont bien l’ensemble de ces caractéristiques (les poids ont un sens même pris individuellement, les poids sont disposés de manière à savoir à quels nœuds (ou liens) ils s’appliquent, il est possible de naviguer dans le modèle pour connaitre les paramètres).
La difficulté reste la protection de cette base de données. En effet, l’article 7 de la directive 96/9/CE prévoit qu’une protection du contenu de la base de donnée peut être accordée « lorsque l’obtention, la vérification ou la présentation de ce contenu attestent un investissement substantiel du point de vue qualitatif ou quantitatif« .
Par obtention, on parle non pas de la création de la donnée mais bien son acquisition. Il faut bien reconnaitre que dans l’entrainement du modèle, ce qui est compliqué c’est la création des données et non son « acquisition ».
Néanmoins, si je devais argumenter, je dirai que l’entrainement du modèle est une sorte de « vérification » de la validité des valeurs des poids de configuration … Dès lors, la protection de l’article 7 de la directive 96/9/CE s’applique t’elle ?
Bien entendu, je n’ai pas de réponse concernant la protection applicable au modèle. Les éléments précédents ne sont que des pistes. Il faudra attendre les jurisprudences.
Les œuvres générées par des IA
Introduction
Je ne suis pas un spécialiste de la protection des œuvres par le droit d’auteur, mais il est vrai que cela serait dommage de ne pas évoquer ce point.
Donc je m’excuse d’avance auprès des spécialistes du sujet de mes approximations.
Quelques exemples
Aujourd’hui, il existe plusieurs « œuvres d’art » produites à partir d’IA :


Mais nous avons aussi de la musique générée par intelligence artificielle (exemple d’un morceau généré par Spotify Research) :
Une protection par droit d’auteur ?
Une fois que nous avons vu ces exemples, il est possible de se demander si ces « œuvres » peuvent bénéficier d’une protection par droit d’auteur.
En droit français, pour bénéficier d’un droit d’auteur (L111-1 CPI), il est nécessaire de vérifier que l’œuvre est « original » (critère jurisprudentiel).
En gros, pour être original, une œuvre doit comporter :
- l’empreinte de la personnalité de l’auteur,
- la marque de l’apport intellectuel de l’auteur et
- l’expression des choix libres et créatifs de l’auteur.
A mon sens, pour les exemples que l’on a vu précédemment, cela ne pose pas vraiment de question : en effet, ces exemples ont été créées par des IA qui ont été configurées (i.e. qui ont subi un apprentissage) précis afin d’obtenir un résultat voulu par l’auteur.
Dès lors, les exemples précédents marquent clairement la volonté de l’auteur d’obtenir un tel résultat.
Nous pouvons considérer que l’IA joue un rôle similaire à un logiciel comme Photoshop ou comme une table de mixage. L’IA simplifie simplement le processus de création.
Bien entendu, il faut regarder au cas par cas et je ne saurais faire une réponse unique de type « toute image ou son sortant d’une IA bénéficie d’un droit d’auteur », mais l’usage d’une IA ne me semble pas exclure, de ce simple fait, l’application du droit d’auteur.
Pour conclure, je voudrais simplement rappeler que, lors de l’invention de la photographie, certains voulaient exclure celle-ci de « l’art ». En effet, ils considéraient que la photographie appartenait au domaine technique.
Ne pensez-vous pas que nous sommes dans la même situation concernant l’IA ?